自動地,背後的公司 WordPress 和 Tumblr 正在洽談透過將其數據出售給人工智慧公司(包括 MidJourney 和 OpenAI。數據來自部落格平台 Tumblr 和 WordPress.com 將用於培訓 mode人工智慧.
儘管交易細節尚不清楚,但這一消息引起了用戶的擔憂,並擔心這兩個部落格平台上的私人內容可能被濫用。 404 Media 也表示,Automattic 內部出現了內部衝突,因為收集的內容包括不打算保留在公司內部的私人資料。
為了應對這種強烈反對,Automattic 將推出一項新功能,讓用戶選擇不共享人工智慧訓練資料。該公司在一篇部落格文章中重申了為 Tumblr 用戶提供服務的承諾 WordPress 更好地控制其內容。它提到啟動了「阻止人工智慧公司探索」的設置,並解釋說預設會阻止領先的人工智慧探索平台。
開發公司使用部落格內容的問題 modele AI 不僅限於 Automattic 公司管理的平台。非常 OpenAI 像 Google 一樣,使用 c 型機器人raw我透過它從所有網站收集資訊來訓練 mode人工智慧樂樂。這個過程類似於搜尋引擎收集資料。
你怎麼能阻止 OpenAI 雙子座(吟遊詩人)從你的部落格中獲取數據?
如果您是部落格或網站的所有者,並且不希望其中的數據用於培訓 mode人工智慧的 OpenAI 和雙子座,你可以阻止機器人(crawlers)到內容。該限制可以透過檔案設置 robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
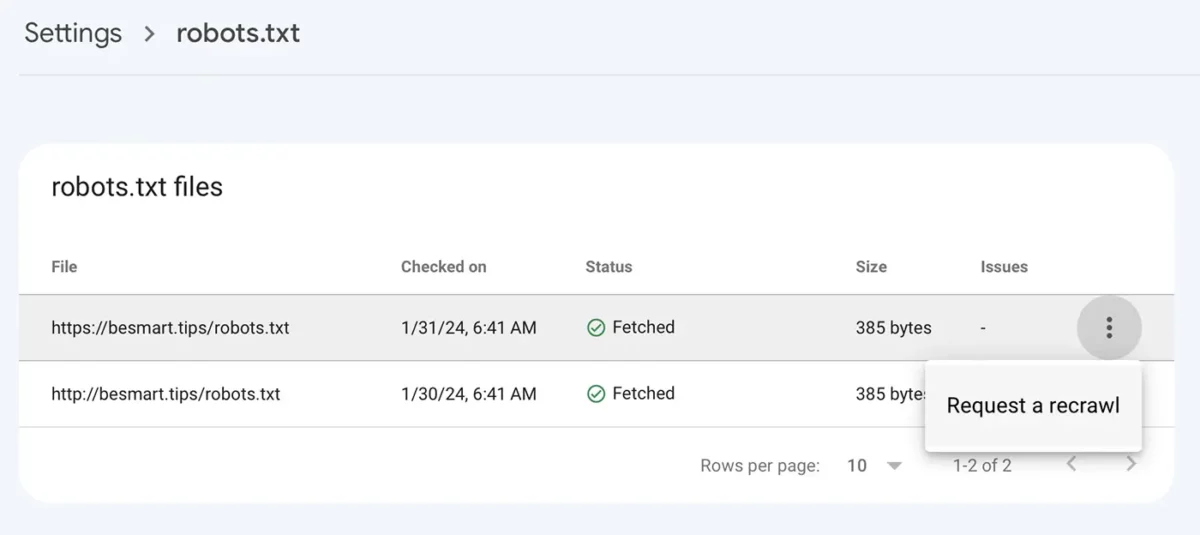
Disallow: /儲存包含新行的 robots.txt 檔案後,請前往 Google Console 以: Settings > robots.txt > 點選有三個點的選單,點選“Request a recrawl“。
相關新聞: GPT-5 和由 OpenAI 開發的新網路爬蟲 GPTBot。
對於 Tumblr 用戶和 WordPress,從部落格檢索資料的訪問 OpenAI 或其他人工智慧開發公司,將能夠透過 Automattic 公司提供的工具進行阻止。